
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- ROS #Robotics #ROS기초
- 리눅스#모의해킹#리눅스명령어#head 명령어
- 파이썬 프로젝트
- 파이썬 #
- 논문번역 꿀팁
- 파이썬 음성파일 텍스트 변환
- 파이썬#파이썬경로#파이썬폴더#파이썬디렉토리
- 파이썬 #파이썬프로젝트 #파이썬 예시 #파이썬 파일경로 #파이썬 자동화
- 파이썬
- pdf 번역
- 파이썬#subprocess#communicate()
- 패스트 캠퍼스 #자율주행 #비전
- 파이썬 파일 전송
- PDF 개행문자
- 리눅스기초#리눅스명령어#리눅스 tail#tail#모의해킹 리눅스
- 통계 #ROC #TPR #FPR #TNR #이진분류 #Accuracy #Recall
- 파이썬 엑셀 파일 읽고 쓰기
- 스트림 암호 one-time-pad 공격#보안#암호
- ROS #spin() #spinOnce() #ROS기초
- 파이썬 텍스트 변환 #파이썬 공부
- 크롬오류#크롬검색어자동완성끄기#검색어자동완성오류#검색어자동완성 제거#검색어 노란선#검색어반복입력
- 파이선 행
- 파이썬 열
- 파파고 꿀팁
- 파이썬 음성인식
- 파이썬 유튜브
- 파이썬 채팅
- 파이썬 예시
- 파파고 번역
- QGC#QGrouncControl#GLIB오류
개발자비행일지
Covariance 공분산 본문
랜덤 변수 X가 있을때 우리가 흔히 이 분포를 나타낼때 쓰는것이
첫번째로 평균이고
두번째로 분산이다.
간단히 말하면, 평균은 분포의 최고점을 알아내고
분산으로써 분포가 얼마나 퍼져있는지 알아낸다.
우선 가장 쉽고 잘표현되는것이 평균과 분산이다.
그렇다면 확률변수가 2가지일때 이 확률분포들이 어떤모양으로 되어있는지를 알고싶을때
가장 먼저 X의 평균, 다음이 Y의 평균이다.
이렇게 되면 대충 분포가 어디에 주로 모여있는지 (m_x, m_y)가 나온다.
각 확률변수들이 퍼져있는 정도가 어떤 상관관계를 가지는지에 대해 나타내는 것이 공분산(Covariance)이다.
즉, X가 커지면 Y도 커지거나 혹은 작아지거나 아니면 별 상관 없거나 등을 나타내어 주는 것이다.
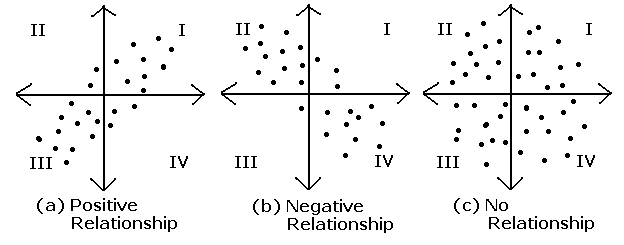
Cov(X, Y) > 0 X가 증가 할 때 Y도 증가한다.
Cov(X, Y) < 0 X가 증가 할 때 Y는 감소한다.
Cov(X, Y) = 0 공분산이 0이라면 두 변수간에는 아무런 선형관계가 없으며 두 변수는 서로 독립적인 관계에 있음을 알 수 있다.
그러나 두 변수가 독립적이라면 공분산은 0이 되지만, 공분산이 0이라고 해서 항상 독립적이라고 할 수 없다.
공분산은 아래와 같이 구할 수 있다.
확률변수 X의 평균(기대값), Y의 평균을 각각

이라 했을 때, X,Y의 공분산은 아래와 같다.

즉, 공분산은 X의 편차와 Y의 편차를 곱한것의 평균이라는 뜻이다.
좀더 간편하게 정리하면 아래와 같다.
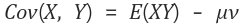
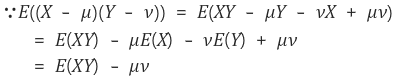
만약에 X와 Y가 독립이면

이므로 공분산은 0이 된다.
그런데 공분산에도 문제점이 하나 있다.
X와 Y의 단위의 크기에 영향을 받는다는 것이다.
즉 다시말해 100점만점인 두과목의 점수 공분산은 별로 상관성이 부족하지만 100점만점이기 때문에 큰 값이 나오고
10점짜리 두과목의 점수 공분산은 상관성이 아주 높을지만 10점만점이기 때문에 작은값이 나온다.
이것을 보완하기 위해 상관계수(Correlation)가 나타난다.
상관계수라는 개념이 왜 나왔는지 생각하다 보면 의외로 간단하다.
확률변수의 절대적 크기에 영향을 받지 않도록 단위화 시켰다고 생각하면 된다.
즉, 분산의 크기만큼 나누었다고 생각하면 된다.
상관계수의 정의는 아래와 같다.

상관계수의 성질을 나열해 보자
1. 상관계수의 절대값은 1을 넘을 수 없다.
2. 확률변수 X, Y가 독립이라면 상관계수는 0이다.
3. X와 Y가 선형적 관계라면 상관계수는 1 혹은 -1이다.
양의 선형관계면 1, 음의 선형관계면 -1
'▶Theory' 카테고리의 다른 글
| iid(independent and identically distribution)란 (0) | 2021.03.31 |
|---|---|
| cardinality 란 (0) | 2021.03.31 |
| 폴링(polling) (0) | 2021.03.24 |
| Prior Probability, Posteriori Probability,Likelihood (0) | 2021.03.23 |
| State transition Matrix, [제어공학] 특성방정식, 상태천이함수 (0) | 2021.03.22 |

